Backgrounds
我最近一直在想,今后的搜广推架构如何发展,在可预见的未来,全图化必然是一个大趋势。
绝大多数搜广推后端技术选型都是分布式微服务框架,各个组件之间通过RPC调用来实现联动:每个微服务应当只承担单一的职责,这使得服务更加易于开发和维护,各个不同业务组件模块化。然而随着系统熵增(业务复杂度骤增,代码库💩山越堆越烂),开发、维护成本 和 协同工作成本逐步升高,新人上手门槛也越来越高。
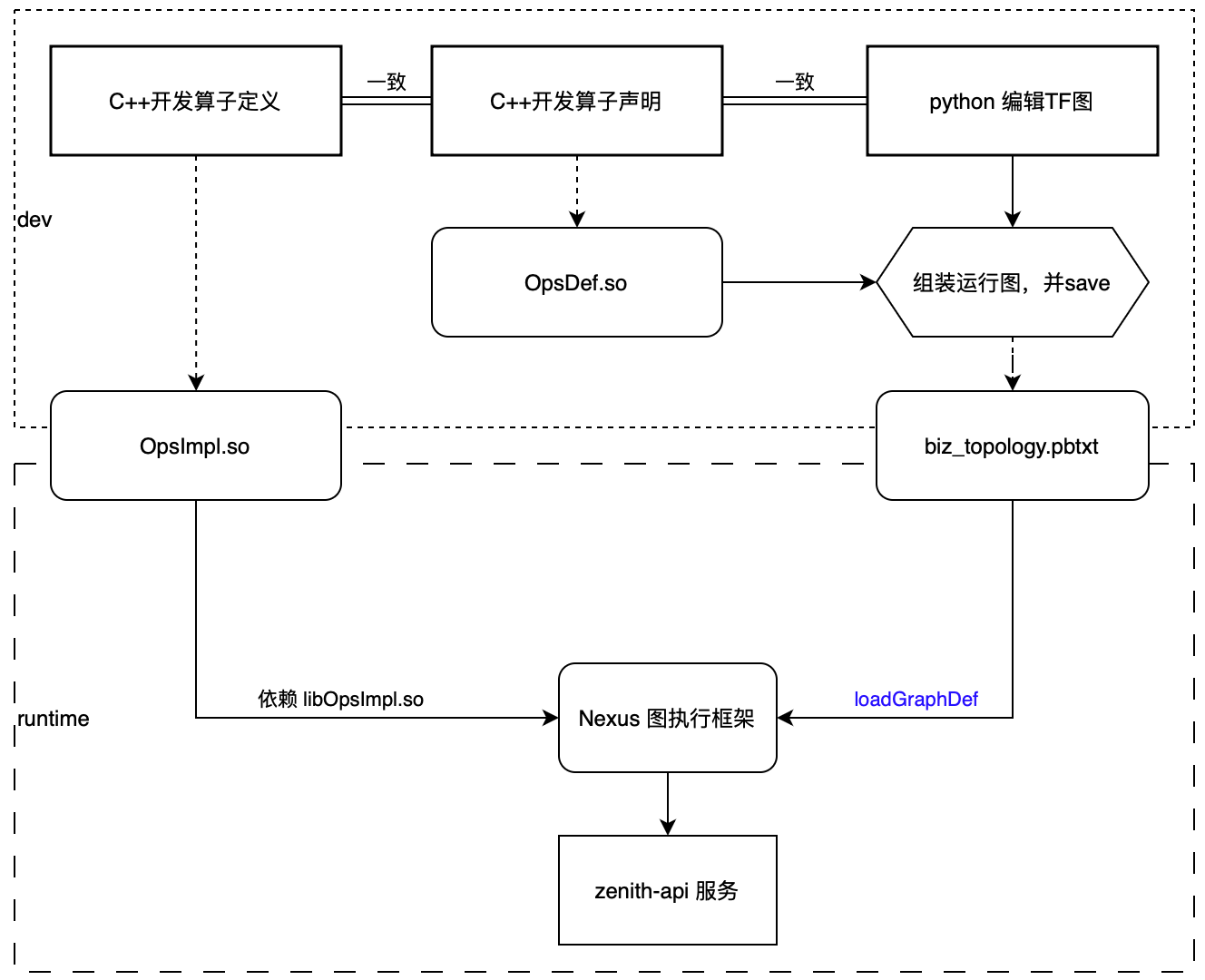
以TensorFlow为代表的机器学习推理框架成为现代搜广推的核心推理引擎之后,召回海选粗精排在线全部的算力分配 和 业务迭代开始围绕着TensorFlow的inference领域展开。于是我在想能否借用TF 分布式图执行框架的能力,将业务逻辑抽象成一个一个的算子,最后的业务逻辑。
Q2刚好有个契机,OKR里有一条hnsw op化的P2需求(我其实更感兴趣,但是得高优推进其他项目,因此zentih/neuxs的代码都是周末在自己的服务器上写的,所以直接放在GitHub作为自己的探索项目了),自己按照TF-Op全图化的思路搭建了一下faiss::HNSW的图化项目。
Overview
开发算子,编辑图,用GraphDef的语言来业务逻辑,用nexus 加载 biz graph,rpc协议转发到 runGraph(调用 session->run),如下:
Op defs
以 RequestInitOp 为例,从HNSW模型中,获取 entry_point 给 GatherNeighborsOp
REGISTER_OP("RequestInitOp") .Input("topk: uint32") .Output("entry_point: uint32") .Attr("index_name: string") .SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) { c->set_output(0, c->MakeShape({1})); return Status::OK(); });
class RequestInitOp : public OpKernel { public: explicit RequestInitOp(OpKernelConstruction* ctx) : OpKernel(ctx) { OP_REQUIRES_OK(ctx, ctx->GetAttr("index_name", &index_name_)); }
void Compute(OpKernelContext* ctx) { auto session_resource = GET_SESSION_RESOURCE(ctx); auto query_resouce = GET_QUERY_RESOURCE(session_resource); auto topk = ctx->input(0).scalar<uint32>()(); query_resouce->candidates = std::make_unique<annop::MiniMaxHeap>(topk << 1); query_resouce->results = std::make_unique<annop::MiniMinHeap>(topk);
query_resouce->visited.resize(session_resource->get_index(index_name_)->neis_->n_, false);
auto entry_point = session_resource->get_index(index_name_)->neis_->entry_point;
Tensor* out = nullptr; OP_REQUIRES_OK(ctx, ctx->allocate_output(0, {1}, &out)); out->flat<uint32_t>()(0) = entry_point; }
private: std::string index_name_;};
REGISTER_KERNEL_BUILDER(Name("RequestInitOp").Device(DEVICE_CPU), RequestInitOp)custom variant
可以自定义variant 作为算子的输入输出,注意实现 encode() 和 decode() 方法就行:
class JsonVariant {public: Json::Value data;
std::string TypeName() const { return "JsonVariant"; }
void Encode(VariantTensorData* data) const { data->set_type_name(TypeName()); Json::StreamWriterBuilder writer; std::string metadata = Json::writeString(writer, this->data); data->set_metadata(metadata); }
bool Decode(const VariantTensorData& data) { Json::CharReaderBuilder reader; std::string errs; const std::string& metadata = data.metadata(); std::istringstream s(metadata); return Json::parseFromStream(reader, s, &this->data, &errs); }};
REGISTER_UNARY_VARIANT_DECODE_FUNCTION(JsonVariant, "JsonVariant");Stateful Resource
TensorFlow 算子是没有状态的,Op内随着请求数据流动到各个算子前后,无法为每一次rpc调用update检索时状态(context)。
我们注意到部分算子可以通过ResourceManager来维护状态,但是在Graph serving的时候,有状态算子在多个并发请求中共享状态,可能导致竞争条件和不一致的状态更新。
OpkernelContext 传递的是设备信息,ResourceMgr等,和biz相关的上下文状态无法通过 OpkernelContext* ctx 传递。我们加了两类Resource:SessionResource 和 QueryResource
SessionResource
struct SessionResource { public: std::vector<QueryResourcePtr> query_resource; IndexManager indexmgr_; private: int max_session_; mutable nexus::utils::Spinlock lock_;};SessionResource在从loadGraphDef创建session 的时候初始化,表征当前这个biz graph加载后需要的那些Resource,如IndexManager,Logger, Metrics等。这些基础资源存在于
我在LocalDevice 类加了一个接口,获取session_resource
class LocalDevice : public Device { public: std::shared_ptr<SessionResource> GetSessionResource() const { return session_resource_; }
std::shared_ptr<SessionResource> session_resource_;}
QueryResource
struct QueryResource {public: std::vector<bool> visited; std::unique_ptr<annop::MiniMaxHeap> candidates{nullptr}; std::unique_ptr<annop::MiniMinHeap> results{nullptr};private: std::vector<std::shared_ptr<nexus::turing::NamedRunMetadata>> run_metas_; RunOptions run_options_; int64_t run_id_;};QueryResource 可以理解为ctx,可以在各个step/node 之间传递一次请求上下文信息,存储在session_resource 中,按照ctx->step_id来对照,
加了几个语法糖, 在OpKernel::Compute(ctx) 的时候,获取query_resource
step_id | run_id
在 TF 中,step_id 是一个用于跟踪每次计算步骤的唯一标识符,特别是在分布式环境或调试中非常有用。它通常在运行计算图时生成,用于标识每个独立的计算步骤。step_id 的生成过程和使用主要与 TensorFlow 的内部执行引擎有关。
每次调用 Session::Run 方法时,都会为当前计算步骤生成一个新的 step_id。这有助于跟踪每个计算步骤的执行,特别是在分布式环境中进行调试或性能分析时。
x
// DirectSession::Run
const int64 step_id = step_id_counter_.fetch_add(1);
TF_RETURN_IF_ERROR(RunInternal(step_id, run_options, &call_frame, executors_and_keys, run_metadata, thread::ThreadPoolOptions()));我们将step_id,从外部传入,单独创建一个RunIdAllocator
x
struct RunIDAllocator {public: void init(size_t); int64_t get(); void put(int64_t);
private: size_t max_session_{1024}; std::vector<bool> bitmap_; mutable std::mutex mtx_;};在session run之前申请 get(),在run结束之后放回 put(runid), 在biz中,也用一个原子变量,来维护这个状态(fetch_sub ,fetch_add):
x
template <typename ReqT, typename RspT>void GraphServiceImpl::process(::google::protobuf::RpcController* controller, const ReqT* request, RspT* response, ::google::protobuf::Closure* done, CreateContextFunc<ReqT, RspT> func) { auto cur = session_id_.fetch_add(1, std::memory_order_relaxed);
auto runid = run_id_allocator->get();
GraphContextArgs argv = biz_->getGraphContextArgs(); tensorflow::QueryResourcePtr qrp = biz_->prepareQueryResource();
argv.run_options.set_run_id(runid);
argv.session_resource = biz_->getSessionResource(); auto ctx = createContext(argv, request, response);
ctx->addQueryResource(runid, qrp);
ctx->run([this, response, done, runid](ErrorInfo&) -> void { done->Run(); run_id_allocator->put(runid); session_id_.fetch_sub(1, std::memory_order_relaxed); });}
Biz Grpah Defs
所有的算子都写好之后,我们可以开始搭建业务的GraphDef了,以HNSW serving为例,将我们一个构建好的faiss::IndexHNSW索引加载到python中,读取meta信息:
levels, max_level
neighbors
entry_point
然后用这些元信息来编辑出一个计算图,并dump 到文本文件中(GraphDef的prototext格式,可读且容易编辑)
xxxxxxxxxx# generate hnsw_graph# author junwei.wang@zju.edu.cnfrom __future__ import print_functionimport tensorflow as tfimport numpy as npfrom tensorflow.python.ops import control_flow_ops # type: ignore
import faissfrom argparse import ArgumentParser
import sys
class HNSWGraphGenerator(object): def __init__(self) -> None: self.parser = ArgumentParser() def addOptions(self): self.parser.add_argument('--hnsw_path', type=str, default='hnsw_1000000.dat') self.parser.add_argument('--output_path', type=str, default='nexus/data/hnsw_model') def parse(self): self.addOptions() options = self.parser.parse_args() self.options = options self.hnsw_path = self.options.hnsw_path self.output_path = self.options.output_path return True
def load_index(self): self.index = faiss.downcast_index(faiss.read_index(self.hnsw_path)) self.entry_point = self.index.hnsw.entry_point self.max_level = self.index.hnsw.max_level self.d = self.index.d print(self.max_level, self.d) def generate(self): g = tf.Graph() with g.as_default(): hnsw_module = tf.load_op_library('/home/yinze/dev/zenith/nexus/nexus/cc/new_nexus_ops_defs.so')
# graph feeds user_emb = tf.compat.v1.placeholder(tf.float32, name='user_emb') hints = tf.compat.v1.placeholder(tf.uint32, name='hints') topk = tf.compat.v1.placeholder(tf.uint32, name='topk') # entry_point at top level entry_point = hnsw_module.request_init_op(topk, index_name="hnsw_demo") nneis_of_layer = 128 neis = hnsw_module.gather_neighbors_op(entry_point, level=self.max_level, index_name="hnsw_demo", nneis=nneis_of_layer) for level in range(self.max_level , -1 , -1): level = level - 1 embs = hnsw_module.gather_embeddings_op(neis, index_name="hnsw_demo", dim=self.d) sims = hnsw_module.gemv_op(user_emb, embs) entry_point_of_next, _ = hnsw_module.indirect_sort_and_topk_op(neis, sims, topk=1000) if level: neis = hnsw_module.gather_neighbors_op(entry_point_of_next, level=level, index_name="hnsw_demo", nneis=64) labels, scores = hnsw_module.result_construct_op(entry_point_of_next, _, index_name="hnsw_demo") with tf.control_dependencies([labels, scores]): done = tf.no_op(name="done") return g
if __name__ == '__main__': gen = HNSWGraphGenerator() if not gen.parse(): sys.exit(-1) gen.load_index() g_def = gen.generate().as_graph_def() with open(gen.output_path + "/faiss_hnsw_graph.pbtxt", 'w') as f: f.write(str(g_def))
可视化 netrion
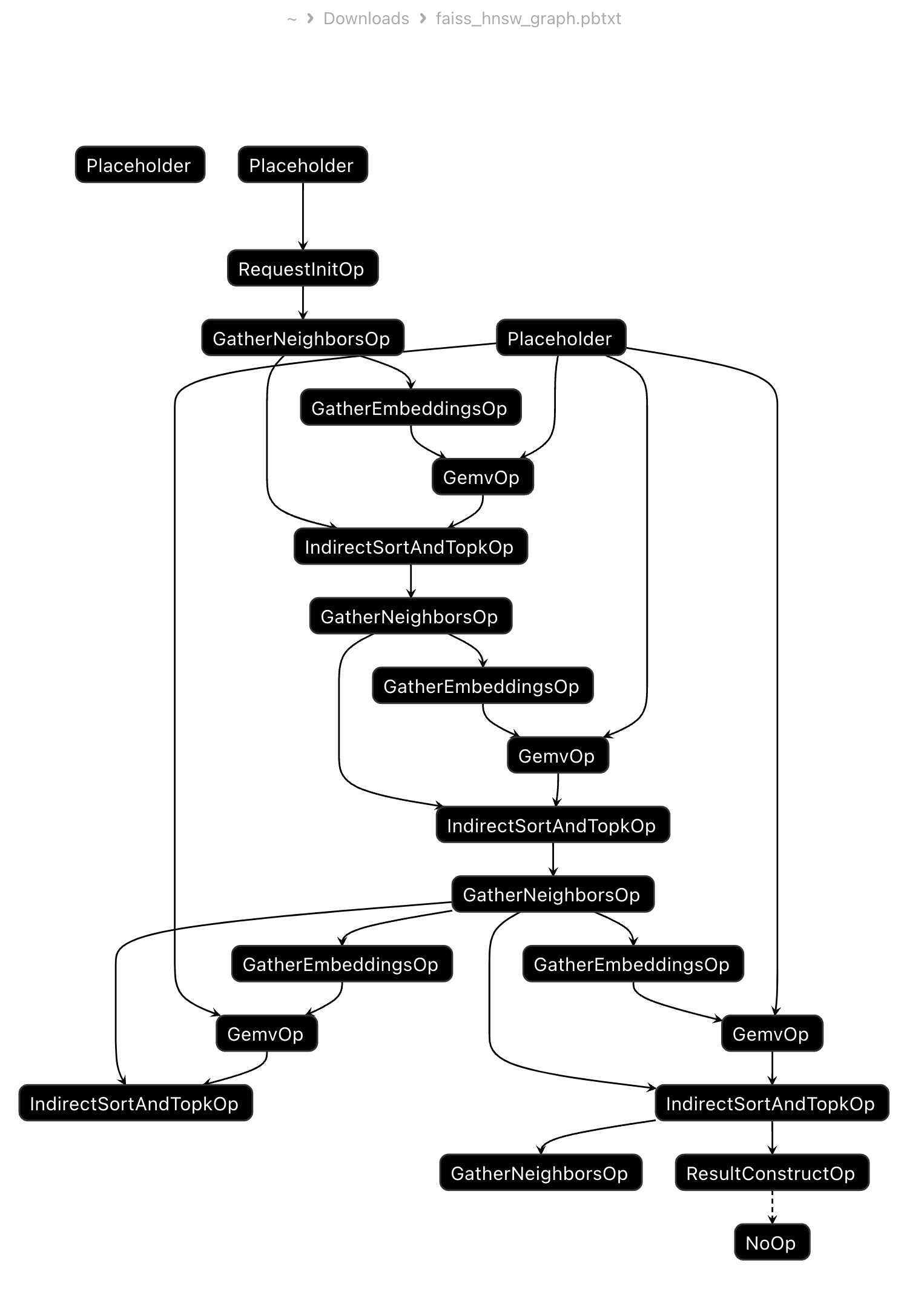
runGraph
在runGrpah 内部,实际调用的 GraphContext::run()
x
void GraphContext::run(CallBack callback) { nexus::common::ScopeDeleter<GraphContext> deleter(this);
ErrorInfo info;
std::vector<std::pair<std::string, tensorflow::Tensor>> inputs;
if (unlikely(!fill_inputs(inputs))) return;
std::vector<std::string> fetches(req->graph_info().fetches().begin(), req->graph_info().fetches().end());
std::vector<std::string> targets(req->graph_info().targets().begin(), req->graph_info().targets().end());
auto status = session->Run(run_options, inputs, fetches, targets, &outputs, &run_metas);
if (status.ok()) { auto it = fetches.begin(); for (const auto& tensor : outputs) { auto tp = rsp->add_outputs(); tensor.AsProtoTensorContent(tp->mutable_tensor()); tp->set_name(*it++); }
auto meta = rsp->add_run_metas(); meta->set_name("default"); *meta->mutable_run_meta_data() = run_metas;
} else { LOG(ERROR) << status.ToString(); } callback(info);}
RPC forward | Delegation
GraphServiceImpl::runGraph,为Session::Run的入口,本地server 需要实现rpc 接口的时候:
将 BizRequest 转换为 GrpahRequest
加载biz,Session::Run
将 GraphResponse 转换为 BizResponse
以ZenithService::Recall为例,ZenithService-> GraphService 的转发发生在服务内部,类似于一个Delegation:
测试效果(WIP)
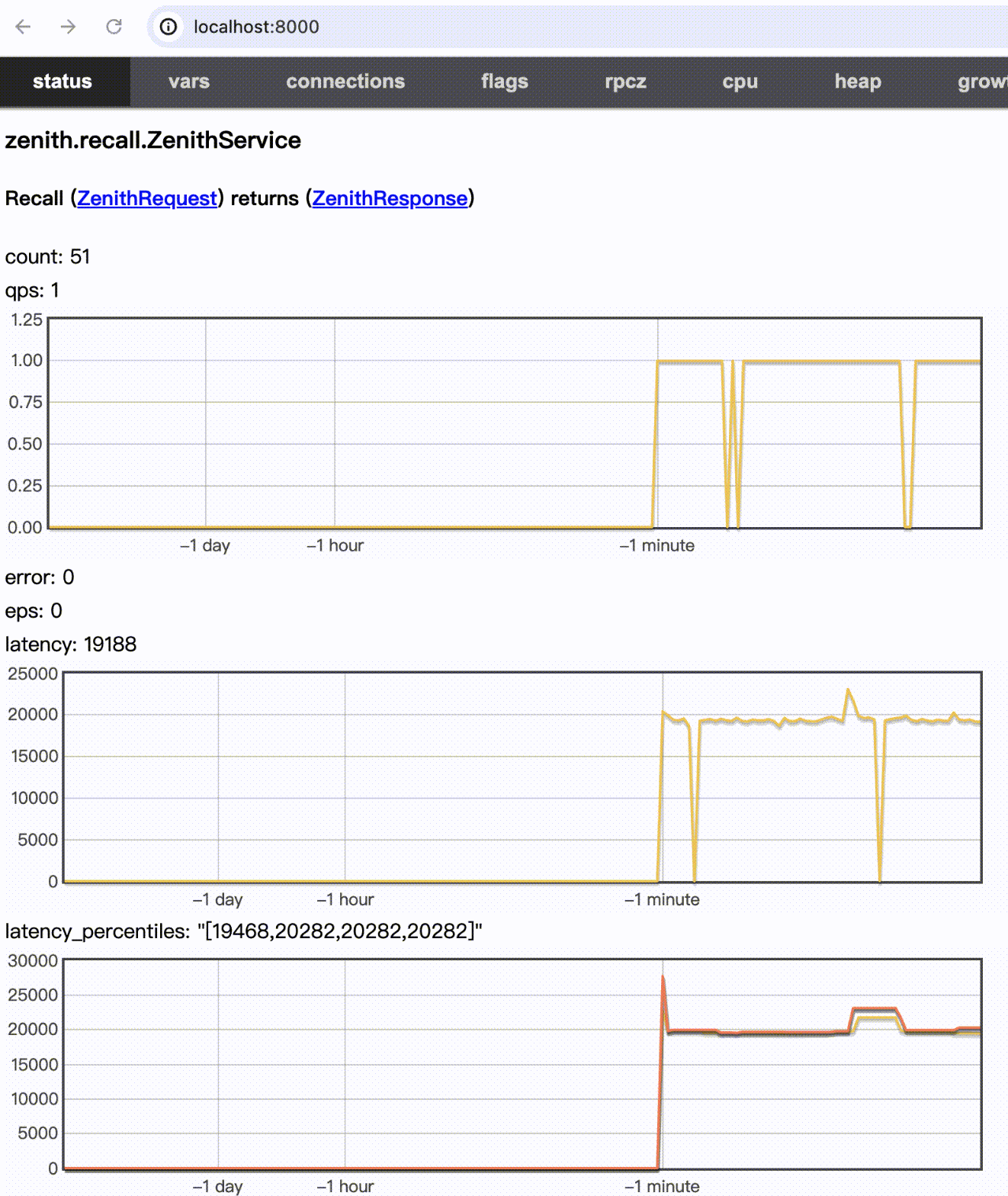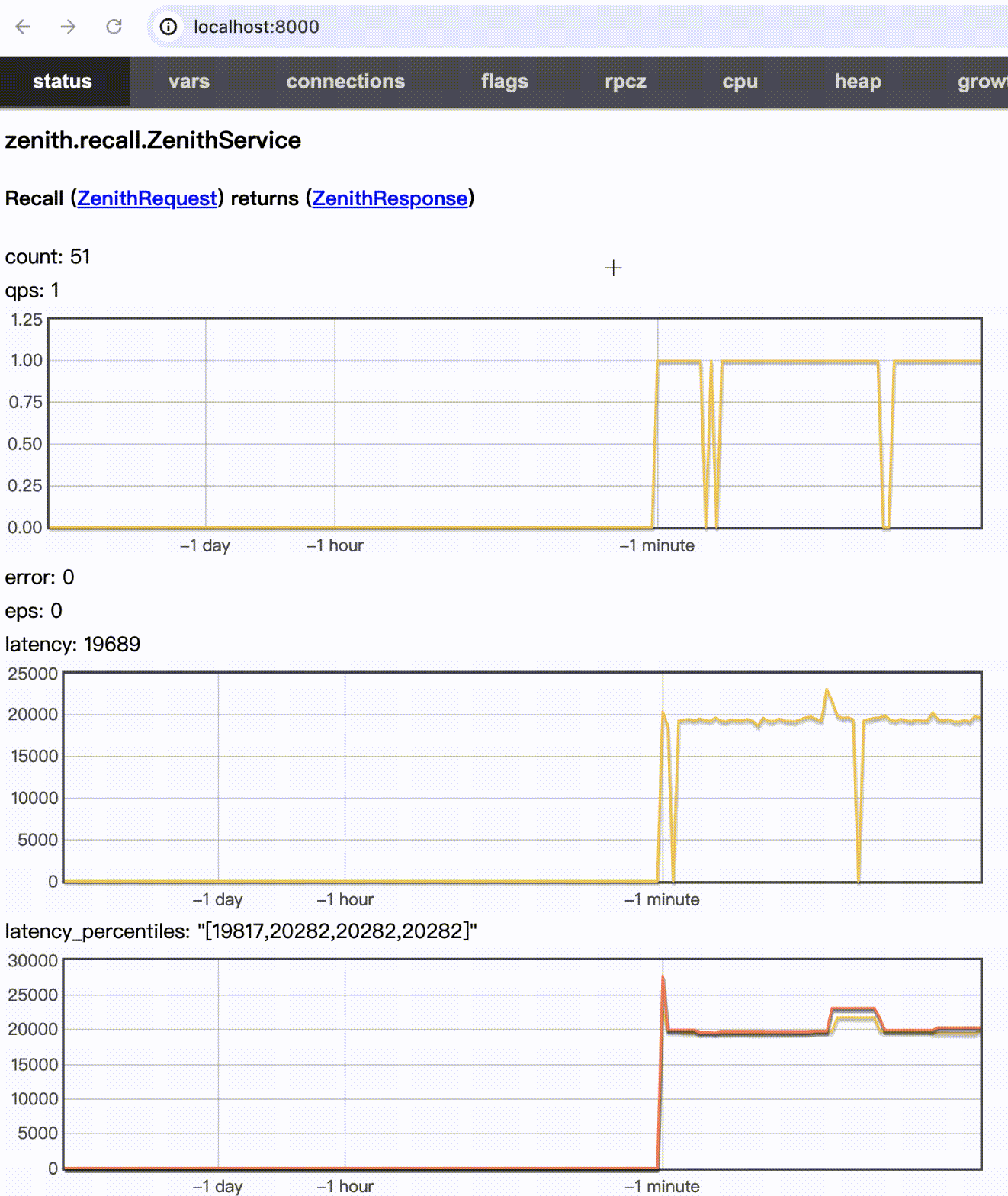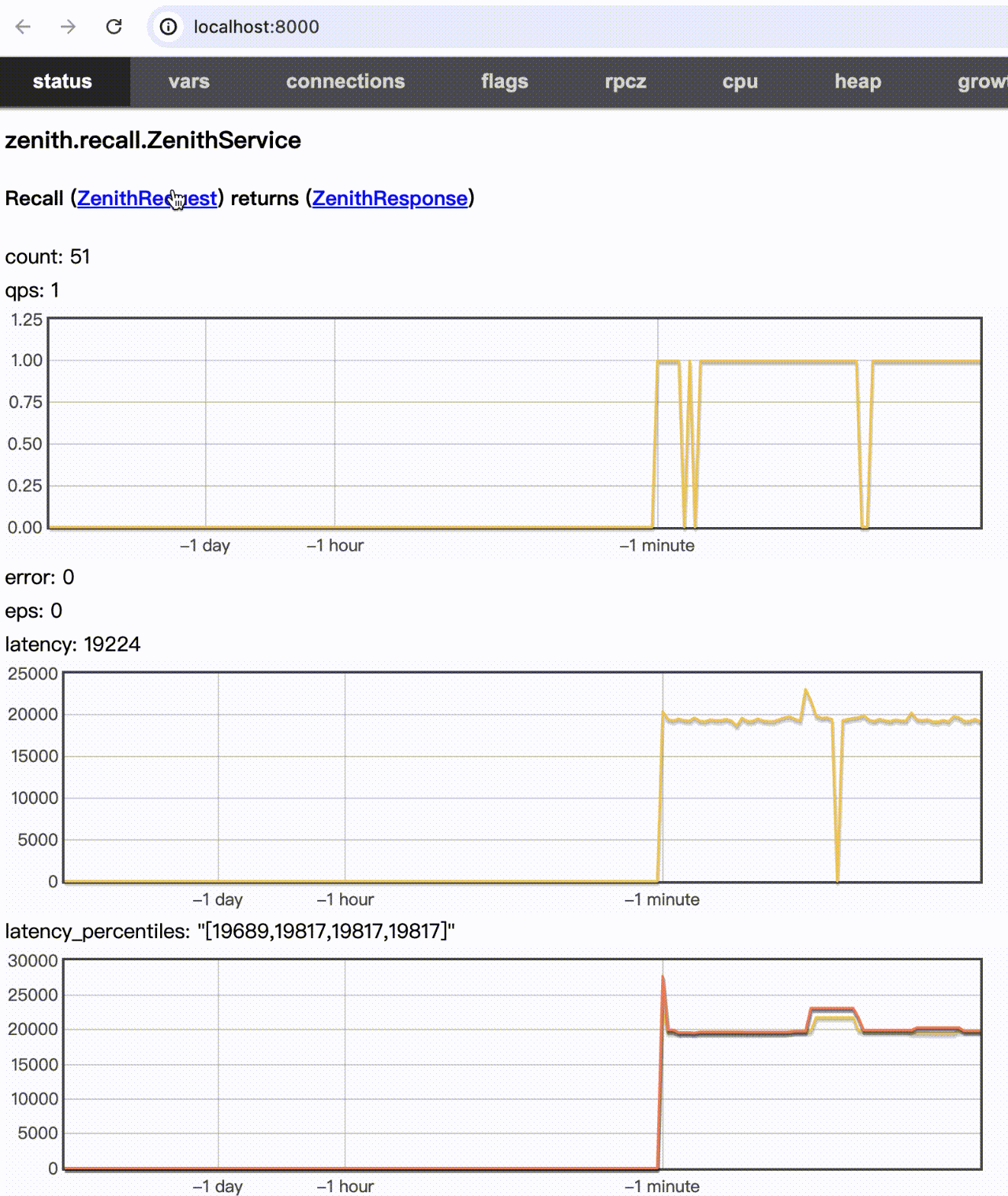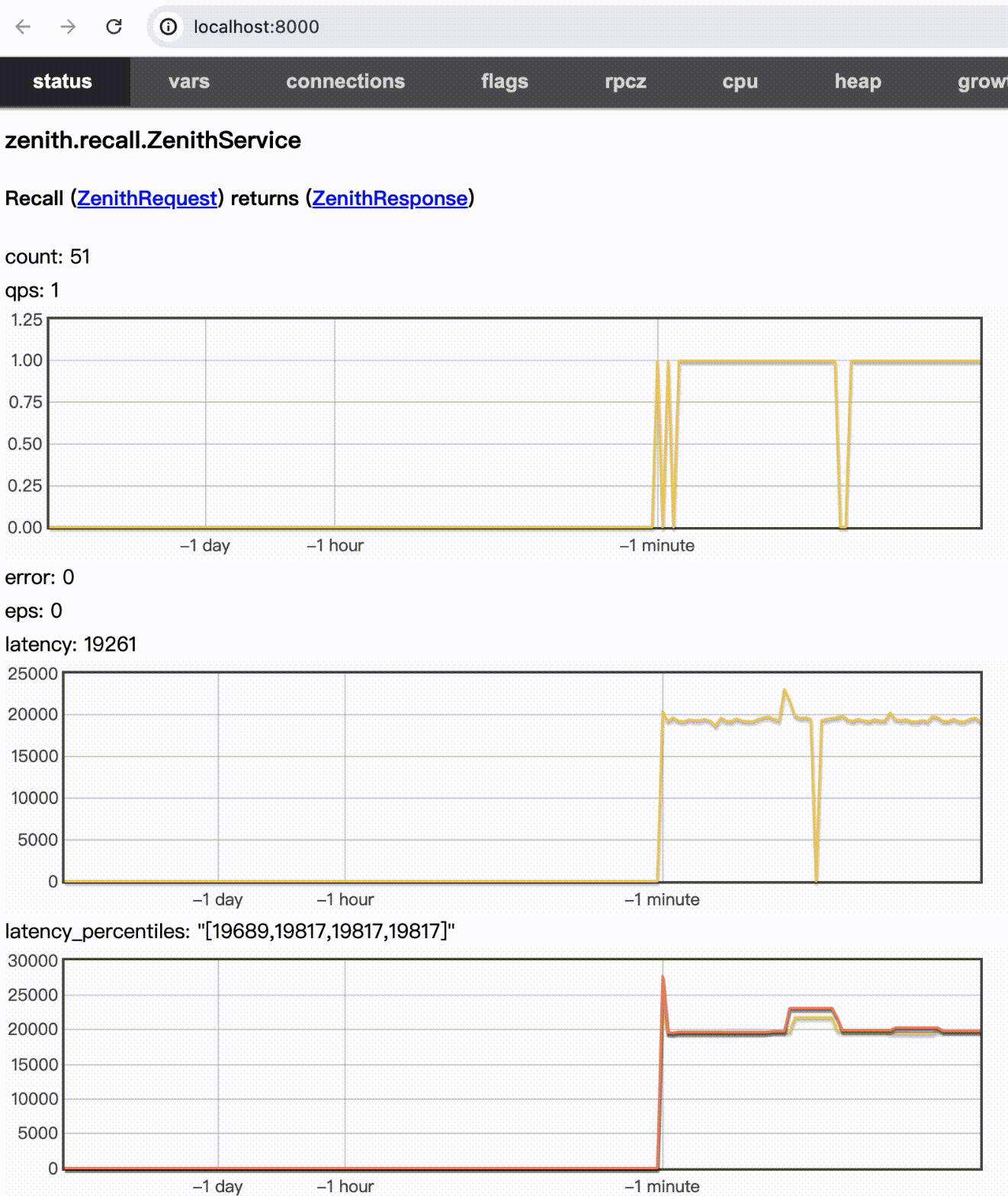
input
xxxxxxxxxx{"message":"Request for LTR-model","query_emb":[0.037073,0.142783,0.200384,0.204126,0.150577,0.024819,0.147724,0.036063,0.158209,0.008027,0.060882,0.134620,0.160528,0.183389,0.118771,0.020973,0.043073,0.035105,0.014197,0.080366,0.110814,0.195470,0.090445,0.033395,0.167452,0.062043,0.063603,0.089272,0.074679,0.195280,0.042334,0.173878,0.035971,0.202347,0.050862,0.075838,0.115146,0.185575,0.170092,0.038238,0.126427,0.002609,0.025100,0.022351,0.151876,0.059745,0.199147,0.142452,0.075618,0.081563,0.072624,0.161117,0.203983,0.173489,0.086655,0.107098,0.183029,0.171412,0.202585,0.162858,0.009639,0.071201,0.032170,0.191455],"topk":100,"index_name":"fb_hnm_v3","biz":"default"}output
x
{"message":"Hello From Server.","gids":[803295,803262,804779,803710,806589,805068,803398,805023,805117,803299,803270,805057,803261,803291,803837,804498,803404,803290,803340,803297,802475,805062,805087,802603,803980,803666,805091,803282,804478,804754,803307,804451,804744,804895,806379,803272,803359,803827,803974,803947,804899,804771,804102,802301,802463,803363,802700,804447,803390,802302,803939,802493,804767,804094,805574,803838,804428,806142,805471,804477,804459,802450,805803,805249,802514,806205,803265,803405,803389,802621,803526,801534,803355,806175,802566,805121,804191,804748,804108,803660,802335,805010,802504,806226,802502,804114,802246,803709,803846,803410,802622,804515,803315,803811,802877,805132,804093,801835,804511,804542],"sims":[6.923573970794678,6.83758544921875,6.76613187789917,6.733438014984131,6.726502895355225,6.681055068969727,6.6802754402160648,6.659149646759033,6.632220268249512,6.617103576660156,6.61536979675293,6.596311569213867,6.589166641235352,6.55383825302124,6.530242919921875,6.51555871963501,6.507923603057861,6.497462272644043,6.488536357879639,6.4719085693359379,6.46926212310791,6.46840238571167,6.468352794647217,6.4632978439331059,6.447779655456543,6.446864128112793,6.445385932922363,6.443720817565918,6.442811489105225,6.440578460693359,6.440252780914307,6.431640625,6.427237033843994,6.423611640930176,6.422511100769043,6.42030668258667,6.419983386993408,6.411962509155273,6.411633014678955,6.411174297332764,6.40372896194458,6.401958465576172,6.399990081787109,6.398940563201904,6.391323089599609,6.387362480163574,6.38660192489624,6.3847432136535648,6.380429744720459,6.3710150718688969,6.370145320892334,6.369976043701172,6.366203784942627,6.36077356338501,6.359500408172607,6.358147144317627,6.357706546783447,6.356125354766846,6.349236488342285,6.3489251136779789,6.346604824066162,6.345465660095215,6.342714309692383,6.342053413391113,6.34034538269043,6.338380813598633,6.330808639526367,6.330255031585693,6.3239593505859379,6.323572635650635,6.321529865264893,6.321380615234375,6.317264556884766,6.305646896362305,6.305125713348389,6.303296089172363,6.302159309387207,6.300145149230957,6.2997283935546879,6.291982173919678,6.289713382720947,6.288875102996826,6.281548500061035,6.277932167053223,6.277278900146484,6.276865005493164,6.2760210037231449,6.272012710571289,6.2663140296936039,6.265318870544434,6.264364719390869,6.263351917266846,6.261058330535889,6.258236408233643,6.257133960723877,6.256979942321777,6.2557759284973148,6.2549967765808109,6.253255367279053,6.253179550170898]}
Reference