LSQ——量化感知训练
随着深度学习的广泛应用,对于模型的压缩和加速变得越来越重要。其中,模型参数量化是一种有效的压缩方法,通过将浮点数参数转换为整数,从而减少了模型的存储和计算开销。本文将介绍一种新的量化方法,即LSQ量化,它可以通过学习量化参数来优化量化误差,并在保持模型精度的同时,大大减少模型的存储和计算开销。
LSQ 量化是一种基于梯度量化和误差反传的低比特量化方法,可以用来将深度神经网络中的权重和激活值量化为较低比特位数,从而减少模型大小、加速推理速度并降低模型能耗。在本篇博客中,我们将详细讲解LSQ量化的原理,包括量化误差的计算、梯度的反向传播以及具体的代码实现。
在深度学习中,模型的参数通常是浮点数,其存储和计算开销较大。为了减少模型的存储和计算开销,可以将浮点数参数量化为整数。假设模型中的参数为w,量化函数为Q,那么量化后的参数为:
Q ( w ) = r o u n d ( w / s ) × s Q(w) = round(w/s)\times s
Q ( w ) = r o u n d ( w / s ) × s
其中,s s s w w w
但是,由于量化会引入量化误差,即量化后的参数与原始浮点数参数之间的误差,因此需要在保持模型精度的前提下,尽可能减少量化误差。传统的量化方法通常使用固定的量化因子和量化函数,无法优化量化误差。为了解决这个问题,LSQ量化方法提出了一种新的量化方法,可以通过学习量化参数来优化量化误差
在量化训练中需要加入伪量化节点 (Fake Quantize),这些节点做的事情就是把输入的 float 数据量化一遍后,再反量化回 float,以此来模拟量化误差,同时在反向传播的时候,发挥 STE 的功能,把导数回传到前面的层。
Fake Quantize 的过程可以总结成以下公式 (为了方便讲解 LSQ,这里采用 LSQ 中的对称量化的方式):
v ˉ = round ( clip ( v / s , − Q N , Q P ) ) \begin{aligned}
& \bar{v}=\operatorname{round}\left(\operatorname{clip}\left(v / s,-Q_N, Q_P\right)\right) \\
\end{aligned}
v ˉ = r o u n d ( c l i p ( v / s , − Q N , Q P ) )
v ^ = v ˉ × s \begin{aligned}
& \hat{v}=\bar{v} \times s
\end{aligned}
v ^ = v ˉ × s
其中, v v v v ˉ \bar{v} v ˉ v ^ \hat{v} v ^ − Q N -Q_N − Q N Q P Q_P Q P Q N 、 Q P Q_N 、 Q_P Q N 、 Q P s s s v ^ \hat{v} v ^ v v v s s s
s = ∣ v ∣ max Q P s=\frac{|v|_{\max }}{Q_P}
s = Q P ∣ v ∣ m a x
接着进入下一轮训练
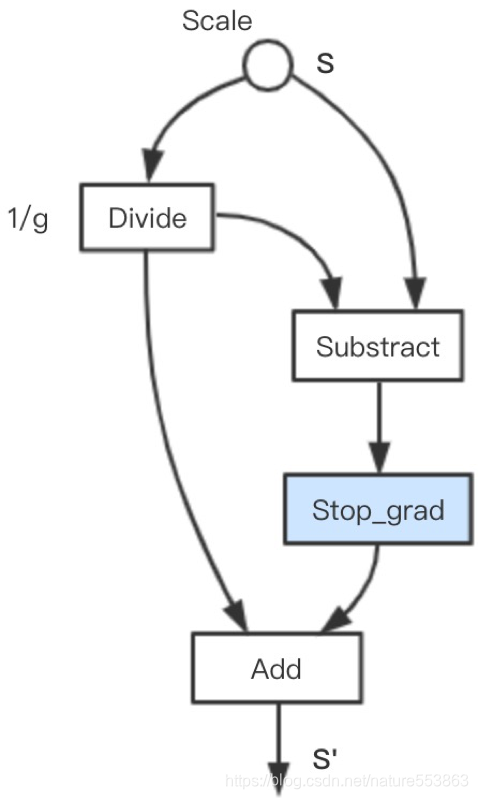
Forward :
s ′ = s g + stop_grad ( s − s g ) s^{\prime}=\frac{s}{g}+\text { stop\_grad }\left(s-\frac{s}{g}\right)
s ′ = g s + stop_grad ( s − g s )
Backward :
∂ L ∂ s = ∂ L ∂ s ′ ∂ s ′ ∂ s = 1 g ∂ L ∂ s ′ \frac{\partial L}{\partial s}=\frac{\partial L}{\partial s^{\prime}} \frac{\partial s^{\prime}}{\partial s}=\frac{1}{g} \frac{\partial L}{\partial s^{\prime}}
∂ s ∂ L = ∂ s ′ ∂ L ∂ s ∂ s ′ = g 1 ∂ s ′ ∂ L
在深度神经网络中,权重和激活值通常是32位浮点数,但这种高精度数据的存储和计算成本很高,因此需要将它们量化为更低比特位数的整数。LSQ量化采用了一种自适应的量化方法,即根据量化误差来动态调整量化参数,从而保证量化后的数据尽可能接近原始数据。
具体来说,假设原始数据为x x x x ^ \hat{x} x ^ Δ \Delta Δ s s s z z z
x ^ = round ( x s ) + z \hat{x} = \text{round}(\frac{x}{s}) + z
x ^ = round ( s x ) + z
Δ = max ( ∣ x − ( s ⋅ round ( x s ) + z ) ∣ ) \Delta = \text{max}(|x - (s\cdot\text{round}(\frac{x}{s}) + z)|)
Δ = max ( ∣ x − ( s ⋅ round ( s x ) + z ) ∣ )
其中,round \text{round} round x x x s s s s s s z z z x ^ \hat{x} x ^ Δ \Delta Δ s s s z z z
LSQ量化对梯度的反向传播做了一些特殊处理,以保证梯度的正确性和有效性。具体来说,假设损失函数为L L L w w w a a a Δ \Delta Δ s s s z z z
∂ L ∂ w = ∂ L ∂ w ^ ∂ w ^ ∂ w \frac{\partial L}{\partial w} = \frac{\partial L}{\partial \hat{w}}\frac{\partial \hat{w}}{\partial w}
∂ w ∂ L = ∂ w ^ ∂ L ∂ w ∂ w ^
∂ L ∂ a = ∂ L ∂ a ^ ∂ a ^ ∂ a \frac{\partial L}{\partial a} = \frac{\partial L}{\partial \hat{a}}\frac{\partial \hat{a}}{\partial a}
∂ a ∂ L = ∂ a ^ ∂ L ∂ a ∂ a ^
其中,w ^ \hat{w} w ^ a ^ \hat{a} a ^ ∂ L ∂ w ^ \frac{\partial L}{\partial \hat{w}} ∂ w ^ ∂ L ∂ L ∂ a ^ \frac{\partial L}{\partial \hat{a}} ∂ a ^ ∂ L ∂ w ^ ∂ w \frac{\partial \hat{w}}{\partial w} ∂ w ∂ w ^ ∂ a ^ ∂ a \frac{\partial \hat{a}}{\partial a} ∂ a ∂ a ^
需要注意的是,由于量化操作是不可导的,因此直接对量化后的数据求导是不可行的。LSQ量化采用了一种近似的梯度计算方法,即将量化误差Δ \Delta Δ L L L
L = L ori + λ Δ L = L_{\text{ori}} + \lambda\Delta
L = L ori + λ Δ
其中,L ori L_{\text{ori}} L ori λ \lambda λ L L L w ^ \hat{w} w ^ a ^ \hat{a} a ^
∂ L ∂ w ^ = ∂ L ori ∂ w ^ + λ ∂ Δ ∂ w ^ \frac{\partial L}{\partial \hat{w}} = \frac{\partial L_{\text{ori}}}{\partial \hat{w}} + \lambda\frac{\partial \Delta}{\partial \hat{w}}
∂ w ^ ∂ L = ∂ w ^ ∂ L ori + λ ∂ w ^ ∂ Δ
∂ L ∂ a ^ = ∂ L ori ∂ a ^ + λ ∂ Δ ∂ a ^ \frac{\partial L}{\partial \hat{a}} = \frac{\partial L_{\text{ori}}}{\partial \hat{a}} + \lambda\frac{\partial \Delta}{\partial \hat{a}}
∂ a ^ ∂ L = ∂ a ^ ∂ L ori + λ ∂ a ^ ∂ Δ
其中,∂ Δ ∂ w ^ \frac{\partial \Delta}{\partial \hat{w}} ∂ w ^ ∂ Δ ∂ Δ ∂ a ^ \frac{\partial \Delta}{\partial \hat{a}} ∂ a ^ ∂ Δ ∂ L ∂ w \frac{\partial L}{\partial w} ∂ w ∂ L ∂ L ∂ a \frac{\partial L}{\partial a} ∂ a ∂ L
下面是一个简单的LSQ量化代码实现,以量化权重为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import torchimport torch.nn as nnclass LSQQuantize (nn.Module): def __init__ (self, nbits=8 ): super (LSQQuantize, self).__init__() self.nbits = nbits self.alpha = nn.Parameter(torch.Tensor([1.0 ])) self.zeta = nn.Parameter(torch.Tensor([0.0 ])) self.register_buffer('init_state' , torch.Tensor([0 ])) self.register_buffer('prev_scale' , torch.Tensor([0 ])) self.register_buffer('prev_zero_point' , torch.Tensor([0 ])) self.reset_parameters() def reset_parameters (self ): self.init_state.zero_() self.prev_scale.zero_() self.prev_zero_point.zero_() nn.init.uniform_(self.alpha, a=0.2 , b=1.0 ) nn.init.zeros_(self.zeta) def forward (self, x ): if self.training: with torch.no_grad(): x_abs = x.abs ().flatten() k = int (x.numel() * 0.7 ) topk_val, _ = torch.topk(x_abs, k) scale = topk_val.mean() / (2 ** (self.nbits - 1 ) - 1 ) zero_point = torch.zeros_like(scale) self.prev_scale.mul_(0.99 ).add_(scale * 0.01 ) self.prev_zero_point.mul_(0.99 ).add_(zero_point * 0.01 ) x_q = x / self.prev_scale x_q = x_q.clamp(-2 ** (self.nbits - 1 ), 2 ** (self.nbits - 1 ) - 1 ) x_q = torch.round (x_q) x_q = x_q * self.prev_scale x_diff = (x - x_q).detach() x_diff_abs = x_diff.abs ().flatten() x_diff_topk_val, _ = torch.topk(x_diff_abs, k) delta = x_diff_topk_val.mean() self.alpha.data = self.alpha.data - 0.01 * (self.alpha.data - (delta / (2 ** (self.nbits - 1 ) - 1 )) self.zeta.data = self.zeta.data - 0.01 * (self.zeta.data - x_q.mean() / self.prev_scale) self.init_state.fill_(1 ) else : x_q = x / self.prev_scale x_q = x_q.clamp(-2 ** (self.nbits - 1 ), 2 ** (self.nbits - 1 ) - 1 ) x_q = torch.round (x_q) x_q = x_q * self.prev_scale return x_q
上述代码实现了一个LSQ量化模块,可以将输入的权重x x x n n n s s s z z z s s s z z z
与传统的量化方法相比,LSQ量化具有以下优势:
更好的量化精度:LSQ量化使用可学习的量化参数来代替固定的量化因子和量化函数,可以更好地适应不同的模型和数据分布,从而获得更好的量化精度。通过学习量化参数,LSQ量化可以优化量化误差,从而在保持模型精度的情况下,减少量化误差。
更少的量化误差:传统的固定量化方法通常使用相同的量化因子和量化函数,无法适应不同的数据分布和模型结构,从而引入大量的量化误差。而LSQ量化使用可学习的量化参数,可以更好地适应不同的数据分布和模型结构,从而减少量化误差。
更小的存储和计算开销:通过量化模型参数,可以将浮点数参数转换为整数,从而大大减少模型的存储和计算开销。而LSQ量化可以在保持模型精度的情况下,进一步减少量化误差,从而进一步减小模型的存储和计算开销。
更好的通用性:LSQ量化可以适用于不同的深度学习模型和应用场景,可以在多种硬件平台上实现高效的推理和训练。LSQ量化可以与其他优化技术结合使用,如剪枝、权重共享和动态计算图等,从而实现更好的模型压缩和加速效果。
相对于LSQ,LSQ+的一个显著区别就是引入了非对称量化 ,把 0 也变成参数进行训练
v ˉ = round ( clip ( ( v − β ) / s , − Q N , Q P ) ) v ^ = v ˉ × s + β \begin{aligned}
& \bar{v}=\operatorname{round}\left(\operatorname{clip}\left((v-\beta) / s,-Q_N, Q_P\right)\right) \\
& \hat{v}=\bar{v} \times s+\beta
\end{aligned}
v ˉ = r o u n d ( c l i p ( ( v − β ) / s , − Q N , Q P ) ) v ^ = v ˉ × s + β
LSQ量化是一种基于梯度量化和误差反传的低比特量化方法,可以有效地减小深度神经网络的模型大小、加速推理速度并降低模型能耗。希望这篇博客对您有所帮助!