Embedding is all you need
Embedding is all you need
入职以来经历过最忙的封闭项目阶段,我终于有空闲下来写点东西了。
我入职当天,还以为自己来写java后端,做搜广推引擎的b端,没想到被分配到来写C++,做的是搜广推引擎的向量召回系统——在一个向量空间内的近似临近搜索问题,简单来说就是疯狂计算向量的余弦相似度 cosA,其中A是query embedding和item embedding的夹角,夹角越小表示物品和用户越相关,越是应该推荐给用户。
于是我开始思考,什么是Embedding呢?
我开始搜索,Embedding是嵌入的概念,用在深度学习领域,用来表征多模态的数据,是对真是世界内实体的抽象表达。
什么是Embedding?
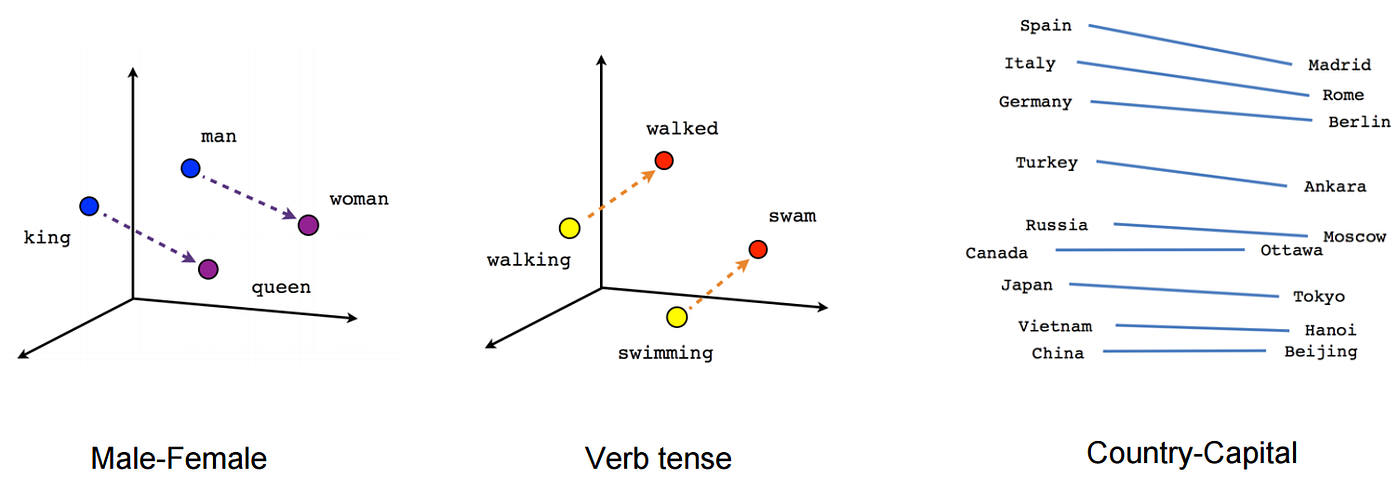
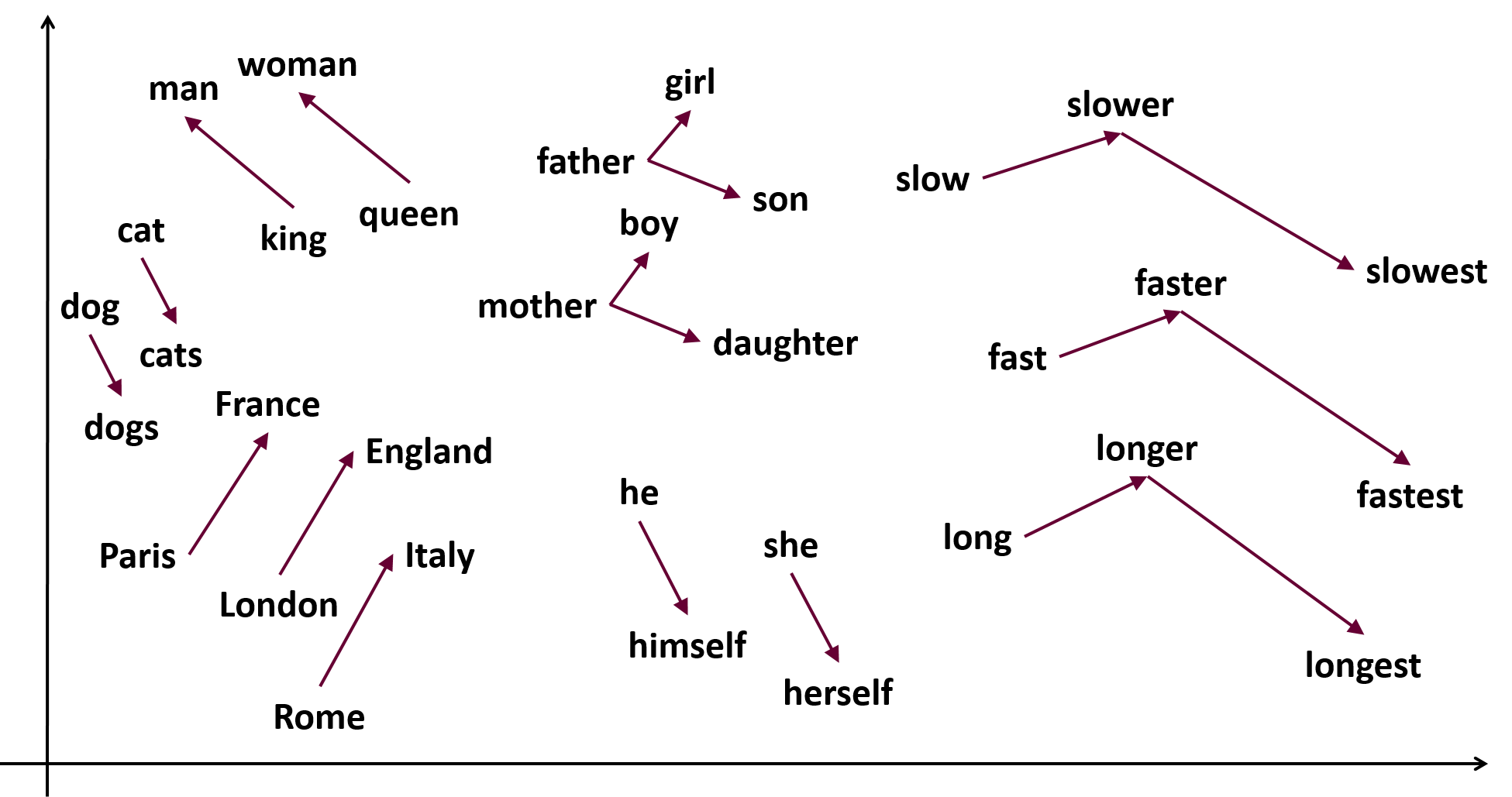
Embedding,即嵌入,是一种将离散型变量(如单词、字符等)映射到连续型向量空间的技术。在NLP和深度学习中,Embedding通常用于表示文本数据,将文本中的单词或字符转换为固定长度的向量。这些向量可以捕捉单词之间的语义关系,为后续的模型训练提供有意义的输入。
为什么需要Embedding?
在自然语言处理任务中,我们需要将文本数据转换为计算机可以理解的形式。最简单的方法是使用one-hot编码,为每个单词分配一个唯一的ID,并将其表示为一个只有一个元素为1,其余元素为0的稀疏向量。然而,这种表示方法存在以下问题:
-
高维度:对于大型词汇表,one-hot向量的维度会非常高,导致计算量大、存储空间占用高。
-
离散表示:one-hot向量无法表示单词之间的相似性,因为任意两个one-hot向量的内积都为0。
Embedding解决了这些问题,将单词映射到低维连续向量空间,同时保留单词之间的语义关系。这使得Embedding在NLP任务中具有更好的性能和更高的效率。
Embedding的原理
Embedding的基本思想是将单词表示为低维连续向量,这些向量可以捕捉单词之间的语义关系。为了实现这一目标,我们需要训练一个模型,该模型可以从大量文本数据中学习单词的向量表示。常见的Embedding方法有Word2Vec、GloVe和FastText等。
Embedding的数学基础
让我们更深入地了解Embedding背后的数学原理。假设我们有一组离散数据点x1,x2,...,xn,其中每个xi属于有限集X。我们的目标是为每个数据点找到一个连续向量表示。
我们可以将Embedding表示为矩阵E∈Rd×∣X∣,其中d是嵌入空间的维度,∣X∣是唯一数据点的数量。矩阵E的每一列对应于数据点的嵌入向量。
要获取数据点xi的嵌入向量,我们可以使用一个one-hot编码向量oi∈R∣X∣,其中所有元素都为零,除了第i个元素为1。嵌入向量ei可以计算为:
ei=Eoi
在训练过程中,神经网络通过最小化特定损失函数来学习嵌入矩阵E。一旦矩阵被学习,它就可以用于获取集合X中任何数据点的嵌入向量。
One-hot Encoding
One-hot编码是最简单的Embedding方法,它将每个离散型变量表示为一个稀疏向量。向量的长度等于所有可能值的数量,向量中只有一个元素为1(表示当前值),其余元素均为0。
例如,假设我们有一个词汇表,包含三个单词:{“apple”, “banana”, “orange”}. One-hot 编码将这些单词表示为:
1
2
3
| apple -> [1, 0, 0]
banana -> [0, 1, 0]
orange -> [0, 0, 1]
|
Word2Vec
Word2Vec是一种流行的Embedding方法,由Mikolov等人于2013年提出。Word2Vec包括两种模型:Skip-gram和Continuous Bag of Words(CBOW)。这两种模型都是基于神经网络的,可以从大量文本数据中学习单词的向量表示。
Skip-gram模型的目标是根据中心词预测周围词,而CBOW模型的目标是根据周围词预测中心词。通过训练这些模型,我们可以得到一个单词与其向量表示之间的映射关系。
Skip-gram
Skip-gram: Skip-gram模型通过给定一个中心单词,预测它周围的上下文单词。它使用中心单词的词向量计算上下文单词的概率分布。Skip-gram模型的优点是对罕见词的处理效果较好,但训练速度较慢。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| class SkipGram_Model(nn.Module):
"""
Implementation of Skip-Gram model described in paper:
https://arxiv.org/abs/1301.3781
"""
def __init__(self, vocab_size: int):
super(SkipGram_Model, self).__init__()
self.embeddings = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=EMBED_DIMENSION,
max_norm=EMBED_MAX_NORM,
)
self.linear = nn.Linear(
in_features=EMBED_DIMENSION,
out_features=vocab_size,
)
def forward(self, inputs_):
x = self.embeddings(inputs_)
x = self.linear(x)
return x
|
CBOW
CBOW(Continuous Bag of Words): CBOW模型通过给定上下文单词,预测中心单词。它将上下文单词的词向量求平均,然后使用Softmax激活函数计算中心单词的概率分布。CBOW模型的优点是训练速度较快,但对于罕见词的处理效果较差。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| class CBOW_Model(nn.Module):
"""
Implementation of CBOW model described in paper:
https://arxiv.org/abs/1301.3781
"""
def __init__(self, vocab_size: int):
super(CBOW_Model, self).__init__()
self.embeddings = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=EMBED_DIMENSION,
max_norm=EMBED_MAX_NORM,
)
self.linear = nn.Linear(
in_features=EMBED_DIMENSION,
out_features=vocab_size,
)
def forward(self, inputs_):
x = self.embeddings(inputs_)
x = x.mean(axis=1)
x = self.linear(x)
return x
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| rom gensim.models import Word2Vec
sentences = [["I", "like", "apples"], ["I", "love", "bananas"], ["I", "hate", "oranges"]]
cbow_model = Word2Vec(sentences, min_count=1, window=2, sg=0, vector_size=4)
skipgram_model = Word2Vec(sentences, min_count=1, window=2, sg=1,vector_size=4)
vector_apples_cbow = cbow_model.wv["apples"]
vector_apples_skipgram = skipgram_model.wv["apples"]
print("Apples vector (CBOW):", vector_apples_cbow)
print("Apples vector (Skip-gram):", vector_apples_skipgram)
|
运行结果:
1
2
| Apples vector (CBOW): [0.18279415 0.12675655 0.16894233 0.01907164]
Apples vector (Skip-gram): [0.18279415 0.12675655 0.16894233 0.01907164]
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| import numpy as np
import pandas as pd
import torch
import sys
from sklearn.manifold import TSNE
import plotly.graph_objects as go
sys.path.append("../")
print(get_top_similar("so"))
folder = "weights/skipgram_WikiText2"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = torch.load(f"../{folder}/model.pt", map_location=device)
vocab = torch.load(f"../{folder}/vocab.pt")
embeddings = list(model.parameters())[0]
embeddings = embeddings.cpu().detach().numpy()
norms = (embeddings ** 2).sum(axis=1) ** (1 / 2)
norms = np.reshape(norms, (len(norms), 1))
embeddings_norm = embeddings / norms
embeddings_norm.shape
|
运行结果
1
2
3
4
5
6
7
8
9
10
11
12
13
| [ 0.02183632 -0.13040318 0.06529056 -0.1869302 0.21838929 -0.15460487
0.08781906 -0.01204591 -0.23110215 -0.13888425 0.06839662 0.03965042
-0.17031781 0.15948693 -0.10498151 -0.07617259 0.02104935 -0.14112245
0.265294 -0.03959387 -0.22041617 0.04864207 0.16093878 -0.12245769
0.19402224 -0.12194688 0.06960531 -0.2695044 0.1003756 0.03097848
-0.23503515 -0.14203762 -0.10973828 0.12561929 0.0853581 0.08054835
-0.06283304 0.00042653 0.20546216 -0.06741708 0.0729891 0.10909085
0.09201632 -0.16548356 0.15943576 0.13922587 0.0192749 0.1434556
0.161938 0.00629455 0.0270902 -0.11881968 0.06717855 0.0005317
0.00320431 0.10809869 -0.03875765 -0.1316357 -0.08824848 0.10125875
-0.00548424 -0.06346093 -0.0599914 -0.00737579]
64
{'too': 0.702025, 'something': 0.6704736, 'feel': 0.65537715, 'actually': 0.64870626, 'pretty': 0.6480339, 'difficult': 0.63854426, 'very': 0.62125194, 'extremely': 0.62103534, 'not': 0.62084544, 'fun': 0.6154798}
|
可见,与so最相似的词是too 都表示太,特别的形容词,在绝大部分句子中,这两个词可以互相替换对方,例如:
- I love you so much
- I love you too much
下图是单词云,所有的词Embedding投影到两个维度

放大之后发现
| word |
Embedding |
| having |
[-4.836869, 63.14442] |
| had |
[-4.542483, 63.11565] |
| has |
[-4.435312, 63.12818] |
| have |
[-3.73602, 63.07804] |

强烈建议前往 🔗word2vec_visualization 体验一下!!!
Embedding的应用
- 自然语言处理(NLP):Embedding广泛应用于NLP任务如情感分析、机器翻译和文本分类。Word2Vec和GloVe等词嵌入技术是将单词转换为连续向量以捕捉其语义含义的流行技术。
- 推荐系统:Embedding可用于表示推荐系统中的用户和物品。通过学习用户和物品的嵌入,系统可以预测用户偏好并进行个性化推荐。
- 图嵌入:在基于图的应用中,Embedding可用于表示连续向量空间中的节点和边。这允许高效计算基于图的算法,并在节点分类和链接预测等任务中获得更好的性能。
- 近似邻居搜索:Approximate Nearest Neighbor Search, 广泛运用于搜索引擎、搜推系统的快速检索阶段,用来从海量数据中检索出最近的一批候选集,也是我正在工作的方向,详情见 🔗Embedding based retrieval
结论
Embedding是深度学习中的一种强大技术,它使我们能够在连续向量空间中表示离散数据。通过捕捉数据点之间的语义关系,Embedding神经网络更有效地处理和学习复杂数据。作为搜广推系统开发师,了解Embedding的概念和应用对于设计和实现高效的深度学习系统至关重要。
参考